Unisteffo
Gestione dell'informazione
Information Retrieval
Cos'è?
È il processo di raccolta documenti, elaborazione query e richiamo di più risposte.
Un'applicazione che effettua IR si chiama motore di ricerca.
Documenti
Sono le unità con cui lavora il motore di ricerca.
Possono essere di vario tipo: pagine web, metadati di file, paper accademici...
Ad esempio, i documenti di Google Search sono le pagine web.

Vengono raccolti in svariati modi: possono provenire da API, essere forniti manualmente e poi processati con un parser, essere scoperti tramite web crawling e processati tramite web scraping...
Un insieme di documenti è detto collezione.
Query
La richiesta di informazioni effettuata da un utente, in un linguaggio che il motore di ricerca è in grado di capire.
In pratica, è quello che scrivi sulla casella di ricerca di Google!

Solitamente vi è possibile inserire parole chiave e operatori per specificare cosa si desidera trovare.
Risposte
I documenti che il motore di ricerca sceglie di mostrare all'utente in quanto li ha ritenuti rilevanti alla query effettuata.
Spesso sono composte da metadati del documento e da un breve estratto della sezione del documento più rilevante.
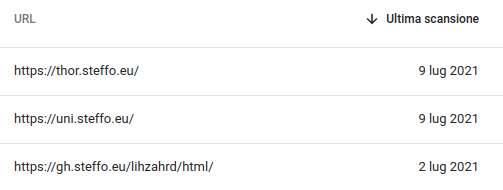
Google Search mostra URL, titolo e descrizione della pagina (o un suo estratto se una descrizione non è disponibile).


Token
Astrazione che rappresenta un singolo significato di una parola o locuzione.
Sono token:
- mela 🍎
- ciao 👋
- forze dell'ordine 👮
- ...
-grammi
Sequenze di caratteri e spazi vuoti (indicati con ␣).
I -grammi assumono vari nomi in base al valore di :
- Bigrammi:
- Trigrammi:
- Quadrigrammi:
- ...
I trigrammi del token ciao sono:
␣␣c ␣ci cia iao ao␣ o␣␣
Preprocessing dei documenti
Cos'è?
Una procedura svolta quando un documento viene aggiunto al motore di ricerca, permettendone l'indicizzazione e in seguito il richiamo.
È suddivisa in varie fasi, generalmente 5 o 6.
1. Analisi lessicale
Tutte le parole del documento vengono trasformate in token.
Spesso si decide di distinguere tra gli Omonimi attraverso algoritmi di word sense disambiguation, in grado di dedurre il contesto analizzando i significati delle parole circostanti.
2. Normalizzazione dei token
Il motore di ricerca decide come trattare i simboli tipografici, la grafia delle lettere, le cifre, modificando l'insieme di token come ritiene necessario.
Alcune possibili modifiche:
- Rimozione degli accenti
caffè → caffe - Rimozione maiuscole non-significative:
Treno per Modena → treno per Modena - Separazione dei trattini
state-of-the-art → state of the art - Correzione dei typo
vetr → vetro
3. Eliminazione delle stopwords
Le stopwords, i token ritenuti inutili ai fini delle ricerche, vengono eliminate dall'insieme di token ottenuto nel passo precedente.
Stopwords comuni sono gli articoli, le congiunzioni e, in generale, tutte le parole più frequenti di una lingua.
Talvolta capita di dover distinguere tra stopwords e nomi propri, soprattutto nell'inglese; per risolvere il problema ci si affida alla disambiguazione degli Omonimi effettuata durante l'analisi lessicale.
4. Stemming / Lemmatizzazione
Ai token del passo precedente vengono sostituite le radici (stems) oppure le forme base (lemmas) delle parole.
Alcune delle operazioni di stemming che possono essere effettuate sono:
- Plurale → Singolare
flowers → flower - Verbo → Infinito
goes → go
Alcune delle operazioni di lemmatizzazione che possono essere effettuate sono:
- Plurale → Singolare
fiori → fiore - Verbo → Infinito
vado → andare
Gli algoritmi che realizzano questo passo sono detti rispettivamente stemmer o lemmatizer.
5. Selezione degli index term
Il motore di ricerca stabilisce la relativa importanza di ciascun token dell'insieme, in modo da determinare più facilmente in seguito la rilevanza del documento in cui si trovano.
I termini più importanti di un documento sono detti index term.
Essi solitamente sono individuati da parser e scanner, che analizzano la semantica di ciascun token.
6. Categorizzazione
Opzionalmente, l'intero documento può essere inserito in una o più categorie di un thesaurus, una gerarchia predeterminata di categorie di documenti.
- [Radice]
- Materiale
- Legno
- Pino
- Betulla
- Mogano
- Pietra
- Legno
- Forma
- Cubica
- Sferica
- Umanoide
- Materiale
Similitudine
Cos'è?
Una misura di quanto due token hanno significati in comune.
uccello e pennuto sono molto simili, in quanto sono sinonimi
merlo e piccione sono abbastanza simili, in quanto sono entrambi uccelli, ma non sono sinonimi
merlo e ala non sono per niente simili
Generalmente si basa su un thesaurus.
A cosa serve?
La word sense disambiguation sfrutta la similitudine tra l'ononimo e i token circostanti per stabilire il significato corretto.
Talvolta alla similitudine sono aggiunte anche altre informazioni, come la distanza tra i token e dati provenienti da sorgenti esterne.
Similitudine path-based
Un modo di misurare la similitudine tra due token basato sulla loro posizione all'interno del thesaurus.
Path-distance
Si basa sull'inverso della distanza tra i due token all'interno dell'albero:
Wu-Palmer
Si basa sulla profondità del minimo antenato comune tra i due token:
Similitudine IC-based
L'IC è una misura probabilistica di quanto un token sia inaspettato all'interno di un documento.
Definendo come la probabilità che un token scelto a caso sia , l'IC sarà:
La similitudine IC-based è quindi un modo di misurare la similitudine basato sull'IC.
Resnik
Si basa sull'IC del minimo antenato comune:
Correzione dei typo
Cos'è?
Una parte della normalizzazione dei token che corregge gli errori ortografici commessi durante l'inserimento della query.
A cosa serve?
Aumenta la soddisfazione dell'utente e gli consente di effettuare ricerche per termini di cui non conosce lo spelling.
Correzione token isolati
È possibile trovare per ogni token dei suoi vicini utilizzabili per migliorare la query:
Tramite edit distance
Dato un token, si cercano tutti i token entro un certo valore di edit distance.
Edit distance
Il numero minimo di operazioni per convertire un token in un altro.
Levenshtein distance
Definisce operazioni le seguenti azioni:
- Inserimento di un singolo carattere
- Rimozione di un singolo carattere
- Sostituzione di un singolo carattere
Matrice di distanza
Matrice costruita per calcolare la distanza di Levenshtein con un algoritmo greedy:
Damerau-Levenshtein distance
Estende la distanza di Levenshtein con una nuova operazione:
- Trasposizione di un singolo carattere
Weighted distance
Differenzia i costi delle varie operazioni, diffenenziando ad esempio in base al carattere sostituito.
m ed n sono vicini sulla tastiera e quindi la loro sostituzione "costa" meno, rispetto a q e p.Calcolare l'edit distance tra due token è un processo computazionalmente molto costoso .
Pre-filtraggio
È possibile evitare di calcolare l'edit distance per la maggior parte dei termini del vocabolario pre-filtrandoli su criteri computazionalmente più veloci.
Differenza di lunghezza
Differenza di -grammi
Posizione dei -grammi
Richiede che venga tenuto traccia delle posizione dei -grammi, e prevede che i -grammi a più di posizioni di distanza non vengano considerati uguali.
Tramite overlap dei -grammi
Dato un token, si ordinano i token del vocabolario in base al numero di -grammi in comune.
Coefficiente di Jaccard
Misura di overlap tra due insiemi di -grammi e :
Usando trigrammi, il coefficiente di Jaccard tra novembre e dicembre è:
- emb mbr bre re␣ e␣␣
- ␣␣n ␣no nov ove vem ␣␣d ␣di dic ice cem emb mbr bre re␣ e␣␣
Tramite algoritmi fonetici
Esistono motori di ricerca che usano un algoritmo per convertire i token nella loro corrispondente pronuncia ed effettuano match sulla base di quest'ultima.
Proposte di correzione
Scoperti i token "vicini", si può optare per varie soluzioni:
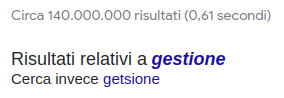
Sostituzione
Sostituire automaticamente il token originale con il più vicino ad esso.
Richiede che le possibili correzioni siano ordinate.
È quello che fa di default Google:

Visualizzazione
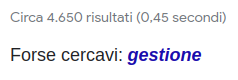
Visualizzare l'errore all'utente, e permettergli di correggerlo rapidamente.
Richiede più interazione da parte dell'utente.
È quello che fa Google quando non è sicuro della correzione proposta:

Aggiunta
Aggiungere automaticamente alla query i token corretti.
Richiede più tempo di ricerca, perchè nella query saranno presenti più token.
Correzione contestualizzata
È possibile confrontare ogni token con il contesto dei termini circostanti per rilevare ulteriori errori.
Conteggio dei risultati
Un metodo che prevede di enumerare varie alternative aventi contesti concordi e di restituire quella con il maggior numero di risultati.
Conteggio delle ricerche
Un metodo che prevede di enumerare varie alternative aventi contesti concordi e di restituire quella che è stata ricercata più volte.
Indici
Cosa sono?
Gli indici sono strutture dati in cui vengono inseriti i documenti e i loro token dopo essere stati preparati.
L'indicizzazione è la procedura che crea e mantiene aggiornati uno o più indici.
A cosa servono?
Sono fondamentali per velocizzare notevolmente le ricerche e per permettere certi tipi di operazioni sulle query.
Matrice di incidenza
Un indice basato sulla costruzione di una matrice in cui le righe sono i documenti, le colonne i token e le celle valori booleani che descrivono se il token compare nel documento.
È terribilmente inefficiente in termini di spazio, perchè la matrice è sparsa.
Una sua evoluzione spazialmente più efficiente è l'inverted index.
Inverted index
L'indice più comune, costituito da tante posting list raggiungibili attraverso un vocabolario.
Posting list
L'insieme di tutte le occorrenze di un dato token.
Può essere realizzata in due modi:
- Document-based: lista ordinata di documenti con la frequenza del token in essi
- Word-based: lista ordinata di documenti che punta a una lista ordinata delle posizioni del token in essi
Essendo le liste ordinate, vi è possibile effettuare operazioni di unione e intersezione in tempo lineare utilizzando dei cursori.
Non è però altrettanto efficiente in operazioni di negazione.
Vocabolario
L'insieme delle associazioni tra token e la loro posting list.
Ci sono tanti modi diversi di implementarlo:
- Doppia lista ordinata: lista di token che punta a una lista di occorrenze
- Trie: albero in cui ogni arco rappresenta una stringa e ogni nodo una concatenazione delle stringhe tra sè e la radice
- Prefix tree: trie che usa i prefissi dei token
- Suffix tree: trie che usa i suffissi dei token
- B+ tree: albero particolarmente ottimizzato, in cui le foglie sono le occorrenze
- Dizionario: hashmap che usa come chiave il token stesso, e una lista di occorrenze come valore
Generalmente, occupano spazio logaritmico rispetto al numero di token.
Query languages
Cosa sono?
Ogni motore di ricerca implementa un diverso query language, un'interfaccia per l'utente che gli permette di effettuare ricerche in base alla sua necessità di informazioni UIN.
site:stackoverflow.com per restringere la ricerca!Ogni query language può poi implementare diverse funzionalità in base al tipo di documento indicizzato.
A cosa servono?
Essendo una via di mezzo tra linguaggio naturale e linguaggio di programmazione, permettono a un utente qualunque di fruire del motore di ricerca, senza bisogno di conoscenze approfondite sul suo funzionamento.
Keywords semplici
All'interno della query vengono inserite una o più keywords da ricercare all'interno dei documenti.
Praticamente tutti i motori di ricerca le supportano!
Divina Commedia DanteKeyword consecutive
Prevedono la possibilità di richiedere che due o più keyword siano consecutive.
Solitamente è possibile specificarlo circondando di virgolette le keyword in questione.
"Nel mezzo del cammin di nostra vita"Keyword distanziate
Prevedono la possibilità di richiedere che due o più keyword siano a una certa distanza una dall'altra.
È molto raro al giorno d'oggi che un motore di ricerca permetta di ricercare la distanza tra le keyword.
Uno dei pochi motori di ricerca che lo permette ancora è Westlaw.
Dante /3 BeatricePatterns
Prevedono la possibilità di cercare prefissi, suffissi, sottostringhe e intervalli di keyword.
Le Regex e i Glob sono i pattern utilizzati più di frequente.
/^V.?rgilio/**/V?rgilio.pngConcetti
Prevedono la possibilità di usare tag provenienti da un thesaurus limitato di cui è garantita la precisione.
Il più famoso motore di ricerca a concetti è PubMed, e i concetti ricercabili possono essere trovati su MeSH.
"Plague"[Mesh]Struttura
Prevedono la possibilità di limitare la query a specifiche sezioni del documento.
Un esempio di query strutturali è Google Books.
inauthor:Dante inauthor:AlighieriOperatori booleani
Prevedono la possibilità di effettuare più query e applicare le operazioni di intersezione, unione e negazione sui risultati.
Moltissimi motori di ricerca permettono boolean query, inclusa la Full Text Search di PostgreSQL.
"Dante" and "Vergil" and ("Devil May Cry" or "DMC") and not "Divina Commedia"Implementazione dei patterns
Tramite prefix e suffix tree
- Separa prefisso e suffisso in due parti collegate da un
AND:ca*e → ca* AND*e - Trova i risultati delle due parti attraverso un doppio vocabolario implementato con sia prefix sia suffix tree:
- ca* → 1:1, 1:8, 2:113, 4:231
- *e → 1:8, 1:32, 2:113, 3:12, 4:1
- Effettua l'intersezione delle due parti:
ca* AND*e → 1:8, 2:113
È costoso in termini di tempo: ci saranno tanti risultati che andranno processati, e l'intersezione è .
Tramite permuterm tree
Permuterm tree
Un particolare prefix tree in cui vengono inserite tutte le possibili permutazioni di ogni token, con in aggiunta un marcatore per la fine della parola (░):
È possibile effettuare ricerche wildcard ruotando la wildcard a destra, trasformando tutti i pattern in prefissi:
- Ricerca semplice:
ciao → ciao░ - Ricerca di prefisso:
ci* → ░ci* - Ricerca di suffisso:
*ao → ao░* - Ricerca di sottostringa:
*ia* → ia* - Ricerca di intervallo:
c*o → o░c*
È costoso in termini di spazio: ogni termine va salvato molte volte nel vocabolario (permuterm problem).
Tramite -gram indexes
-gram index
Vocabolario aggiuntivo che associa -grammi ai token corrispondenti del vocabolario principale.
È possibile interpretare la ricerca come intersezione di -grammi:
Utilizzando dei bigrammi:
AND lu AND unI risultati della ricerca andranno post-filtrati, in quanto ci potrebbero essere dei falsi positivi:
Utilizzando dei bigrammi:
AND mo AND on → È un'ottima via di mezzo tra prefix-suffix tree e permuterm tree sia per il tempo impiegato sia per lo spazio richiesto.
Modelli di IR
Cosa sono?
Sono modelli matematici in grado di selezionare e ordinare i documenti in base alla loro rilevanza rispetto alla query.
A cosa servono?
Stabiliscono i risultati richiamati dal motore di ricerca e l'ordine con cui vengono visualizzati.
Modelli classici
Rappresentano la query come un insieme di index term, e assegnano le rilevanze confrontando l'insieme con gli index term dei documenti.
Ad ogni index term del documento viene indipendentemente assegnato un peso in base alla sua rilevanza nella query.
Modello booleano
Modello classico che rappresenta la query come un predicato booleano, e genera la rilevanza valutandolo su ogni documento:
1se il predicato è vero0se il predicato è falso
Modello fuzzy
Variante del modello booleano che permette ai documenti di soddisfare parzialmente il predicato:
1.00se il predicato è vero0.XXse il predicato è parzialmente vero0.00se il predicato è falso
Le operazioni fuzzy diventano quindi:
AND:OR:NOT:
Modello vettoriale
Modello classico che rappresenta il vocabolario come uno spazio vettoriale, in cui ogni dimensione rappresenta un token.
Ogni documento viene rappresentato come un vettore , i cui valori sono pesi assegnati in base a quanto il token è signficativo all'interno del documento.
Le query vengono anch'esse trasformate in vettori , e le rilevanze vengono ottenute dalla similitudine vettoriale tra i vettore query e i vettori documenti.
Peso tf-idf
Un metodo di assegnamento peso che si basa sul prodotto dei fattori e :
: Term frequency
Misura quanto un token è frequente nel singolo documento:
Nella formula principale, viene normalizzato dividendolo per il più alto del documento, limitandolo così a valori tra 0 e 1:
: Inverse document freq.
Misura quanto un token è raro nella collezione di documenti:
Nella formula principale, viene logaritmizzato, al fine di ridurre significativamente il suo impatto:
Similitudine vettoriale
Un modo di misurare la similitudine tra insiemi di token rappresentati come dimensioni vettoriali.
Coseno di similitudine
Si basa sulla norma a 2, e corrisponde a cercare l'angolo centrato all'origine tra i due vettori:
Altre misure comuni di similitudine vettoriale sono:
Modello probabilistico
Implementazione del modello vettoriale che ordina i documenti in base alla probabilità che siano rilevanti per la query :
Si dimostra che è possibile determinare quanto la presenza di un dato token in un documento ne contribuisca alla rilevanza per la query :
Il valore del primo "blocco" dipende dalla presenza del token nei documenti rilevanti: più il token vi appare, più il valore sarà alto.
Il valore del primo "blocco" dipende dalla presenza del token nei documenti non rilevanti: più il token vi appare, più il valore sarà basso.
Modello Okapi BM25
Modello classico che ordina i documenti in base a un punteggio RSV ad essi assegnato.
L'RSV deriva dalla somma per ogni termine della query del prodotto di tre fattori:
Fattore
Un moltiplicatore basato sull' dei termini della query presenti nel documento:
Fattore
Un moltiplicatore basato sulla nel documento dei termini nella query:
Ad esso viene in genere applicata una normalizzazione basata sulla lunghezza del documento:
Fattore
Un moltiplicatore basato sulla nella query stessa dei termini nella query:
Ad esso non viene ovviamente applicata alcuna normalizzazione.
Link Analysis Model
Modello per classificare documenti intercollegati in base a come essi sono collegati tra loro.
PageRank
Algoritmo di Link Analysis Ranking query-independent che assegna un grado a ogni pagina indicizzata.
Rank
Misura iterativa di quanto una pagina è importante rispetto a tutte le altre indicizzate.
In cui:
- è una pagina che referenzia quella in questione;
- è il rank normalizzato della pagina ;
- è il numero totale di link presenti nella pagina ;
- è una sorgente di rank;
- è un parametro che regola l'emissione della sorgente di rank e la dissipazione del rank preesistente.
Sorgenti di rank
Funzione che introduce nuovo rank nel sistema ad ogni iterazione.
PageRank normale prevede che questa funzione sia costante; è possibile però personalizzarlo rendendo la funzione variabile, facendo in modo che vengano assegnati rank più alti a certi tipi di pagine.
Rank normalizzato
Rank riscalato a valori inclusi tra 0 e 1.
Solitamente, il rank viene rinormalizzato ad ogni iterazione.
HITS
Algoritmo di Link Analysis Ranking query-dependent che attribuisce due diversi valori ad ogni pagina: autorità e hubness.
Viene applicato solo a un base set, ovvero all'unione del root set (i match della query) con tutti i nodi ad essi direttamente connessi.
Autorità
Misura di quanto la pagina in questione viene referenziata da altri siti autoritativi.
Hubness
Misura di quanto la pagina in questione referenzia siti autoritativi.
Autorità normalizzata
Autorità riscalata a valori inclusi tra 0 e 1.
Hubness normalizzata
Hubness riscalata a valori inclusi tra 0 e 1.
Profilazione sistemi IR
Cos'è?
Misurazioni che vengono effettuate sui sistemi di IR.
A cosa serve?
Per vedere quanto funziona bene un sistema di IR!
Benchmark
Per ottenere delle misure, solitamente si preparano in anticipo delle query dette benchmark delle quali si è già a conoscenza dei documenti rilevanti.
Misure comuni
Le due misure usate più di frequente per misurare l'utilità dei risultati sono recall e precision.
Recall
Misura quanti documenti rilevanti sono stati richiamati dalla collezione:
Precision
Misura quanti documenti richiamati sono rilevanti:
Misure derivate
R-Precision
La precisione di una query che richiama elementi.
R-Recall
A precisione , il richiamo relativo ad una query.
Curva di richiamo
Curva che associa percentili di richiamo ai corrispondenti valori di R-Precision.
Ad esempio:
| Richiamo | R-Precision |
|---|---|
| 10% | 90% |
| 20% | 60% |
| 30% | 10% |
| ... | ... |
| 100% | 2% |
È detta naturale se include un punto per ogni documento richiamato.
È detta standard se usa le percentuali da 10% a 100% come punti.
Curva di richiamo interpolata
Mostra il valore massimo di precisione per valori di richiamo maggiori o uguali a quelli del punto.
Ad esempio:
| Richiamo | Precisione | Interpolata |
|---|---|---|
| 10% | 90% | 90% |
| 20% | 40% | 50% |
| 30% | 30% | 50% |
| 40% | 50% | 50% |
| ... | ... | ... |
| 100% | 2% | 2% |
Misure medie
Esistono misure che riassumono i risultati di più benchmark in una sola.
Curva di precisione media
Se si hanno più benchmark, corrispondenti a più curve di richiamo, si possono ottenere le medie dei valori ai vari livelli, ottenendo così una curva di precisione media.
Mean average precision
La media di tutti i livelli di precisione media.
Media armonica
Misura che combina richiamo e precisione in un singolo valore:
Misura E
Complemento della media armonica configurabile che permette di selezionare se dare priorità alla precisione () oppure al richiamo ():
Discounted Cumulative Gain
Misura che attribuisce guadagni decrescenti in base alla precisione di ogni documento richiamato.
Una formula per il DCG potrebbe essere:
Applicata, sarebbe:
| Posizione | Stelle | Punti |
|---|---|---|
| 0 | ★★★★☆ | |
| 1 | ★★☆☆☆ | |
| 2 | ★★★☆☆ | |
| 3 | ★★★★★ | |
| Tot | ----- |
Normalized DCG
Variante del Discounted Cumulative Gain che divide il punteggio finale per il valore perfetto ottenibile.
Normalizzando la formula precedente si ottiene:
Presentazione
Cos'è?
Il modo in cui i risultati vengono visualizzati all'utente.
A cosa serve?
Permettere all'utente di vedere velocemente tutti i risultati e di scegliere il risultato a lui più utile.
Elenco di collegamenti
Il motore di ricerca web mostra all'utente un elenco di collegamenti ai documenti richiamati.
Solitamente include alcuni dati del documento, come titolo, sommario e url.
Sommario
Un breve riassunto del contenuto del documento richiamato.
Sommario statico
Un sommario i cui contenuti dipendono solo dal documento, e non dalla query immessa.
manifest.json, dai tag OpenGraph, dalle prime righe del documento e quelli che Google genera dalle applicazioni web (Web 3.0).Sommario dinamico
Un sommario che varia da query a query, evidenziando le parti rilevanti del documento.